Virtualization? Emulation?
What are these, after all?
- Virtualization in our context here means that when a guest operating system does computations, these get directly offloaded to the hypervisors cpus. One of the benefits is performance, one of the downsides is that the guests cpus need to exactly match the hypervisors cpus, or a subset.
- Emulation means that the computations are done in software. With this, host/guest architectures can be different. As a downside, this is slower than virtualization.
Using emulation, we can for example start a x86 based system, and then emulate completely different architectures like ARM or sparc64. How much performance does that cost us, how much power does this consume?
The setup
I’m experimenting since some time with setups to measure the electical consumption of systems, the setup is described in more detail here and here. The summary: I’m using a Thinkpad T590 (x86 architecture) with Fedora to measure power consumption of the cpu/memory/gpu components. The Intel cpu exposes these via RAPL mechanism. The Performance Co-Pilot (PCP) framework is constantly measuring and archiving these metrics for me, so I can use this archive to ’travel back in time’ and look at the metrics at any point in the past.
With the measurements running, I do these:
- run the virtual guest to me measured, for example a guest with emulated arm64 architecture
- then I run Ansible scripts from the hypervisor, these copy further scripts into the guest, into a RAM disk
- then workloads are run in the guest, each workload for 300 seconds
- after each workload I capture how often the workload was running in the guest (for example how often a file got unzipped in these 300sec), and I capture the power which was consumed on the hypervisor.
The hypervisor is for these measurements not running other workloads, the bigges workload is the emulation of the guest.
As workloads, I try to cover the main resources which are relevant:
- compute power: I measure how often a file can be uncompressed
- network throughput: iperf2 and iperf3 are used
- memory: for this, I write block files with zeros into a RAM disk
- disk I/O: - let’s read and write blocks of data in the guest, with and without sync
For all of there, I’m not only curious on the actual performance in the guest, but also how much electrical power was used. As for operating system in the guest: Linux is not really covering many architectures, that’s the strong point of NetBSD.
Notes on emulating the single architectures
- ARM64 is quite solid: emulating 16GB of memory is no issue. 32 cpus is also possible, but then the 8 cores of my hypervisor are 100% busy. I settled with emulating cpu cortex-a53, after cpu=cortex-a57 and cpu=max turned out slightly slower.
- The NetBSD RISC-V port is quite new, instead of doing an installation of the stable/released version 10.x I had to use the 10.99.12 development version. With that, I did not see signs of instability. My measure scripts use sudo, iperf3 and bash - for stable NetBSD on aarch64, sparc64 and so on I could fetch and install these as precompiled packages but here I compiled these myself, with pkgsrc.
- sparc64 with the sun4u architecture is just getting emulated by qemu with one cpu and up to 2GB of RAM. NetBSD has also since some versions problems to access ATA bus (for the emulated disc) and the network card. A 100Mhz UltraSPARC-IIi cpu gets emulated. Both NetBSD and OpenBSD have issues to run on this emulation, interrupts scheduling related to ATA disk and network card are involved.
- sparc, I used ‘sun sparc 20’ emulation, configs with 4 cpus and 2GB RAM can be configured. When running ‘iperf’ or doing block I/O to ramdisk, the guest system did run into stalls for me. To replicate, execute ‘mount_mfs -s 1200m -u chris swap /dev/shm’ and then ‘dd if=/dev/zero of=/dev/shm/1gbfile bs=1m count=1024’. The cpu bound workloads did run without issues, or I/O to disk. Another obersvation: even with more than one cpu emulated, the performance does not increase with multiple threads started.
- AMD64/x86_64 is of course matching my hypervisor for these tests, so besides emulating ("-cpu Icelake-server-noTSX") I did for reference also run NetBSD with KVM, so virtualized. I did also run it virtualized with KVM and Linux as guest, but then with a much more complex qemu config - not started by hand with “qemu-system-x86_64” but with a config suggested by libvirt.
- i386 turned out also quite stable, I emulated and benchmarked 2 configs: “-cpu qemu32-v1” and “-cpu pentium2” to see how much they are different.
Comparing CPU power over the architectures
Qemu is emulating the various architectures differently “well”, restricted to numbers of cpus and so on. Also NetBSD does not support all architectures equally well, i.e. for some it is limited to a single cpu. I looked at cpu power like this:
- spawn a number of threads with bash: 1, 2, 4 or 8
- inside each of the threads run a loop which extracts a file (‘bzcat file’), increases a counter of completed extractions, and jump back to extracting the file again.
- So there run multiple ’extraction loops’ independent of each other. If these loops match the number of cpu cores, then each loop gets scheduled to run on it’s own core
- We run these loops for example for 5min, then we kill the loops and collect the number of completed extractions
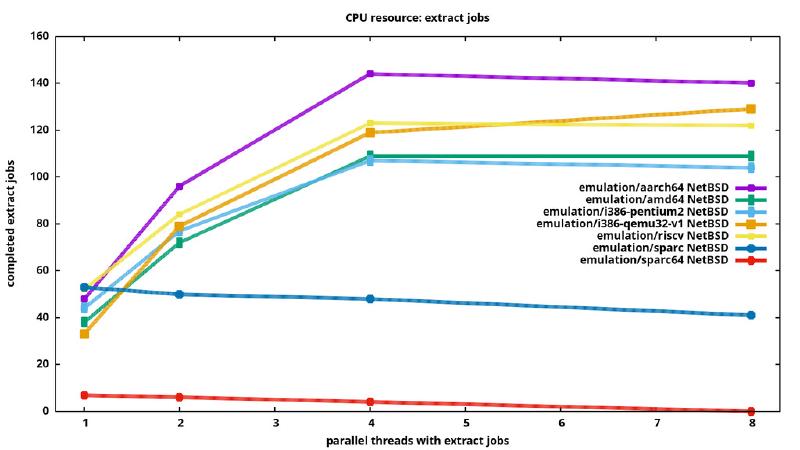
Let’s have a look:
From the left to the right, the number of ‘parallel jobs’ was increased. On the left, for “1”, one loop which concstanly extracted the same file was running for 5min. qemu can emulate multiple cpus for most architectures, so when 4 loops with extract jobs run in parallel, the maximum of work is getting done. As we increase the number of parallel threads further, the threads do no longer have one cpu.
The red line at the bottom is from the sparc64 emulation, as mentioned before
it did not run properly. Also just a single cpu could be used. The blue line
in the middle is ‘sparc’: performing better, but even when configured with
4 cpus just one seems to get load. Then the area of well emulated
architectures: i386 on the lower end, and aarch64 at the top end.
Differences also in this field are quite big: with 4 parallel threads,
i386-pentium2 completes 107 jobs, while aarch64 completes 144 jobs.
That’s 34% more!
Network and Disk I/O
How about the other resources?
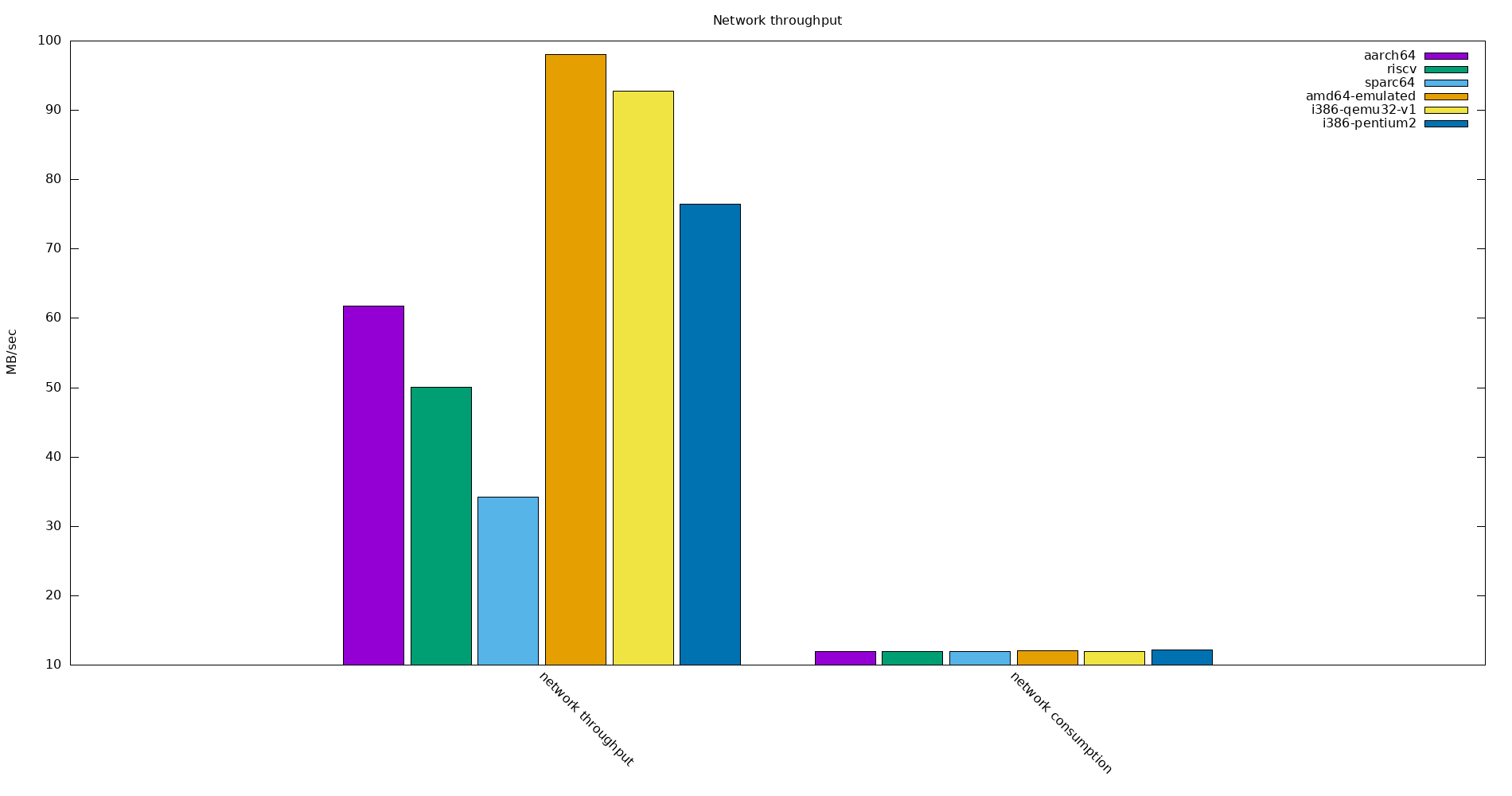
Quite some variety here, the x86 based architectures have the best network throughput. This was tested with iperf3, and for ‘sparc’ with ‘iperf2’.
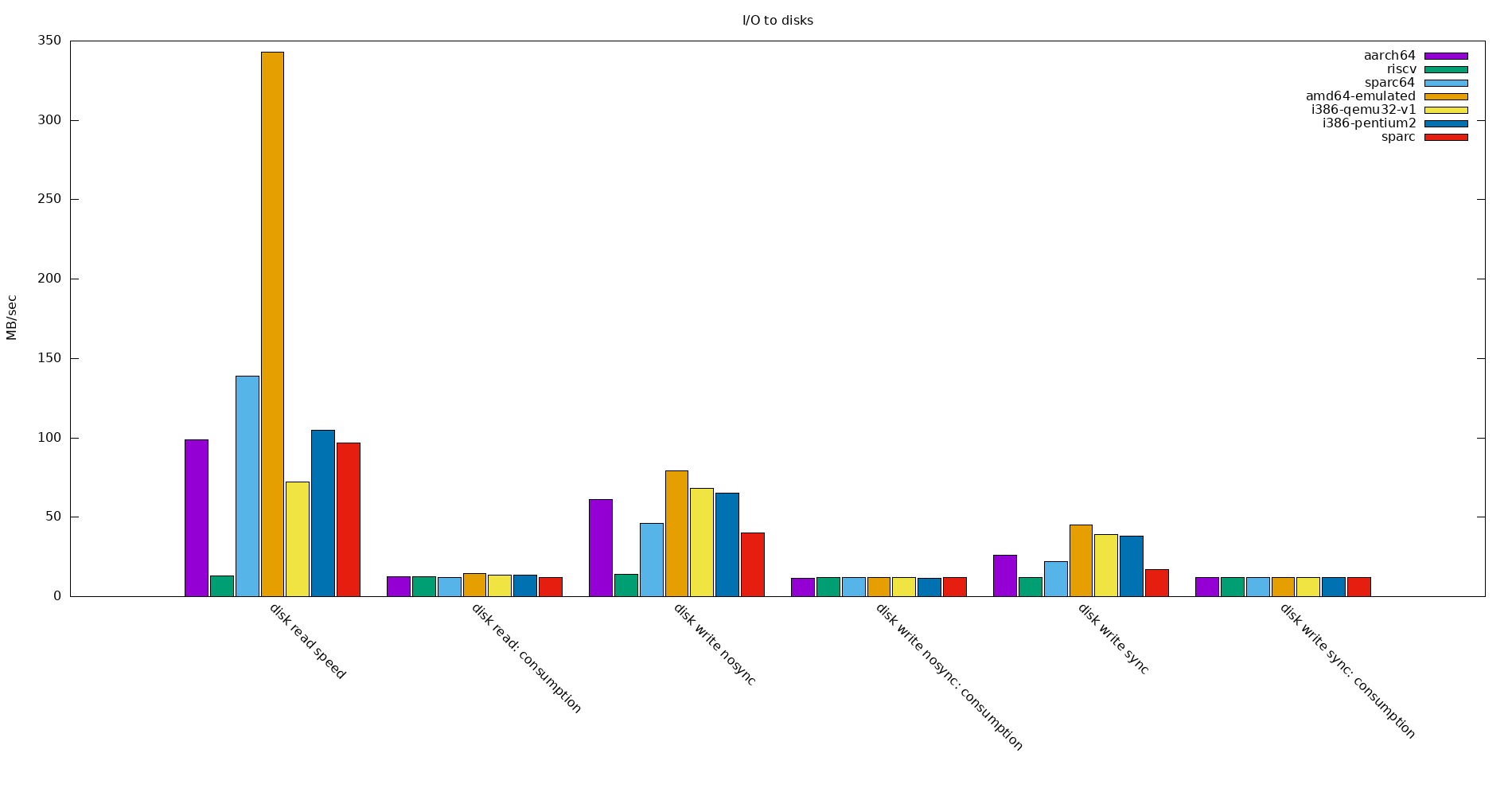
For I/O to disks, the reads for the emulated amd64 are exceptionally fast, I tested that value multiple times. Also big variety among the others: RISC-V is slowest for reads, that’s why compiling there was so painfully slow for me. Energy consumption over all of the architectures is more or less same while performing these tests. The energy is here measured with the cpu RAPL-MSR metrics, via pmda-denki.
Energy efficiency
If we would emulate systems to do raw computing, how efficient are they? In other words, to extract a bzip2 file in the emulated guest, how much electrical power is spent?
For this, I was looking at RAPL-MSR metrics again. Various metrics are available, for example “overall system consumption”, so for example consumption of nvme and attached USB-devices are also counted in that metric. I was here using the metric for the cpu/memory/gpu subsystems. These consume power even when nothing gets computed. The more cpus we can use for our computations, the better gets our “power per extract-operation” value.
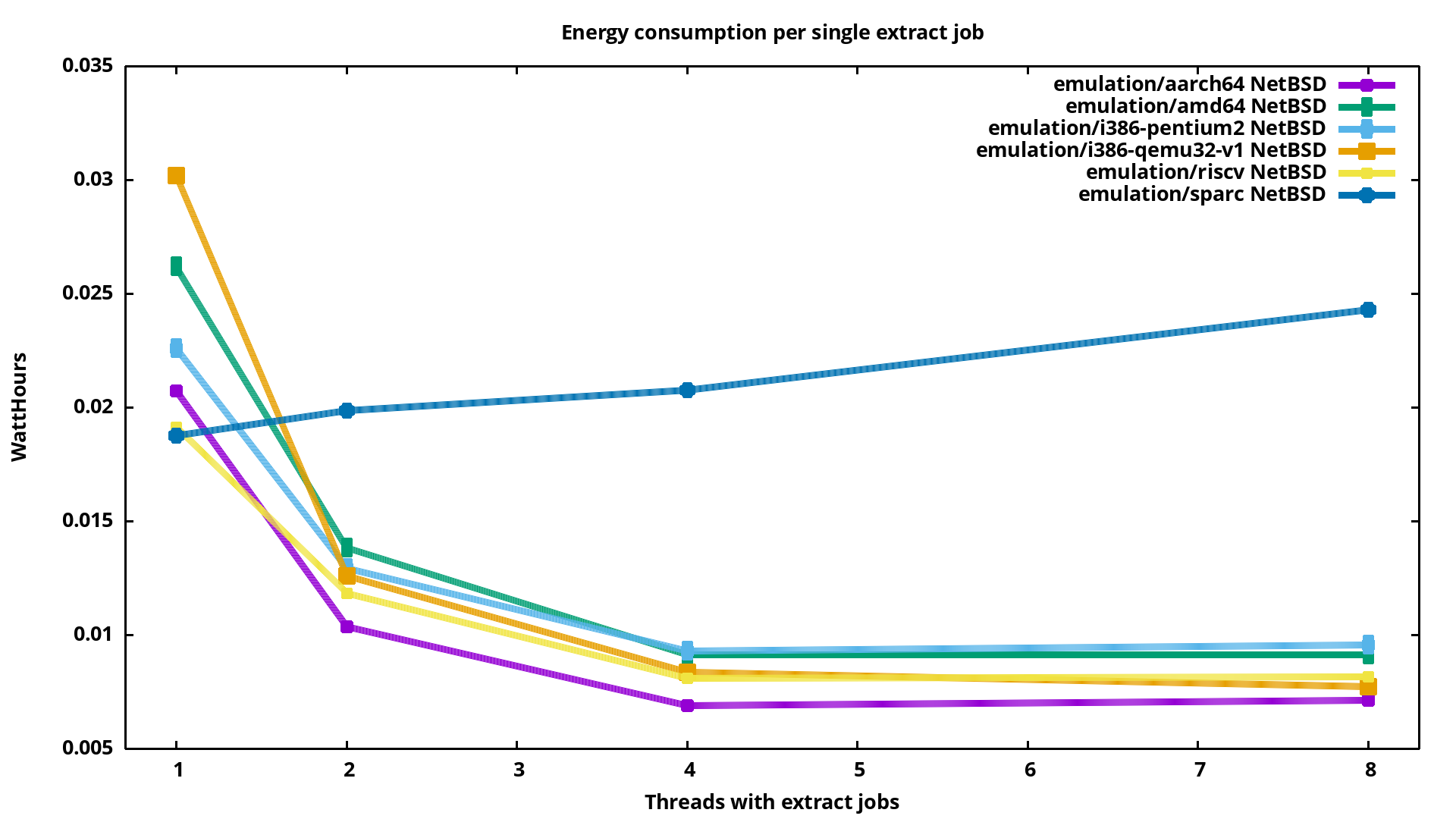
Here we see nicely how sparc is using just a single cpu, and starting more jobs is just making the efficiency worse. The other architectures have 4 cpus, so the consumption per single extract operation goes down until 4 threads, and is then increasing.
Summary
If you are not after performance, emulation for most architectures is usable. Most architectures are stable enough to just try operating systems like Solaris. NetBSD is the most flexible candidate to cycle through various architectures and everywhere find the same environment for benchmarking. ‘aarch64’ emulation turned out quite performant, if your hypervisor has many cores then you can afford to also emulate many guest cpus. RISC-V worked surprisingly well. Getting the whole setups and tests to run took quite some time, but was fun.
I just looked at qemu here, but there are many more options, some are listed here. There is so much more to try in this area: use BSD as hypervisor. Verify if for example aarch64 as hypervisor shows the same performance. Try other BSD and Linux as guests. I’m also curious about performance of emulators for consoles like SuperFamicon, or Amiga, and compare how efficiently they emulate their target while producing graphical output.
I will soon do a performance comparison of emulation and virtualization. What would you like to see?
Corrections? Questions? -> Fediverse thread
Links
- the job control scripts
- PCP pmda-denki handbook
- Raw data of the tests, images etc. are here