TL’DNR
In this article I will look into the details of a special case with fully emulated systems, where an older Linux distro performs better than a new one. I will use RHEL7 and RHEL10 here, but the difference can also be seen with other distros. This is limited to the not very common case of the system running as a fully emulated environment, for example with QEMU. Most environments run virtualized guests instead.
Terms
I will use the terms like this:
- Virtualization in our context here means that when a guest operating system does computations, these get directly offloaded to the hypervisors cpus. One of the benefits is performance, one of the downsides is that the guests cpus need to exactly match the hypervisors cpus, or a subset.
- Emulation means that the computations are done in software. With this, host/guest architectures can be different. As a downside, this is slower than virtualization.
Background
Why would one run emulation instead of virtualization? I use an aarch64 based laptop for work. To replicate issues of x86 systems I use full system emulation. This research helped me to understand speed differences between the various x86 cpu/chipsets which can be emulated, and I made an observation:
The command for emulating a guest:
| |
Some of the x86 chipsets which QEMU can emulate, 147 right now:
The initial observation
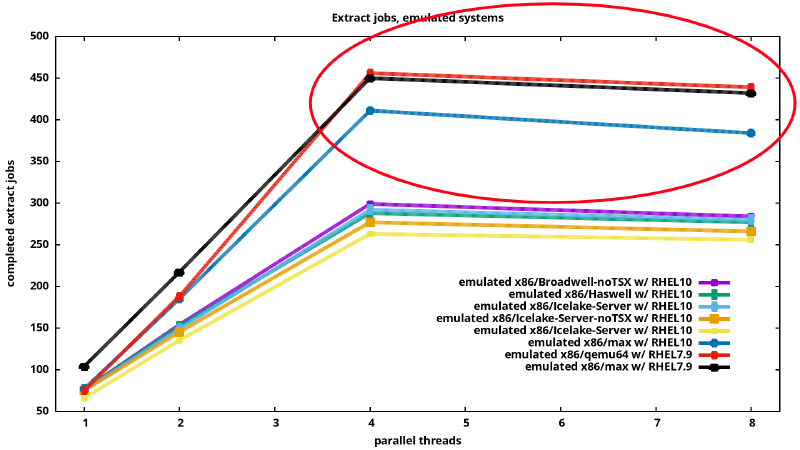
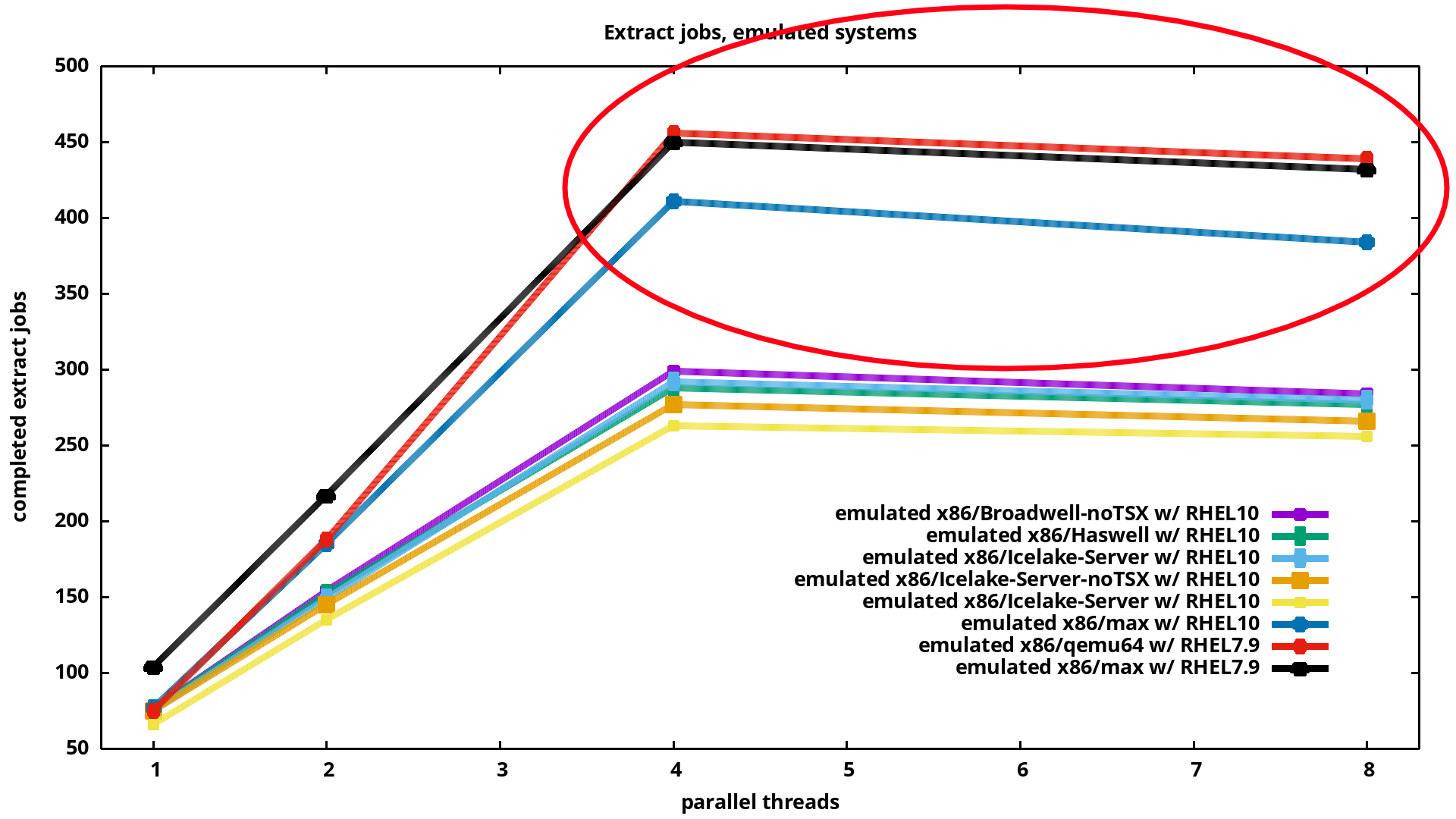
I was curious if all of these emulated systems perform same, or some are faster, so better suited for my uses. I did run CPU bound workloads in the guest, visualized them. On the following graph, starting from the left, we see a single thread doing “file uncompress jobs” for 10minutes.
| |
Running 2 threads in parallel, the number of extract jobs increases.
Even more for 4 threads. These are systems with 4
emulated CPUs, so with 8 threads we see the number of extraction jobs
declining a bit. On this graph we can see RHEL7 doing better than
RHEL10:
Why is that?
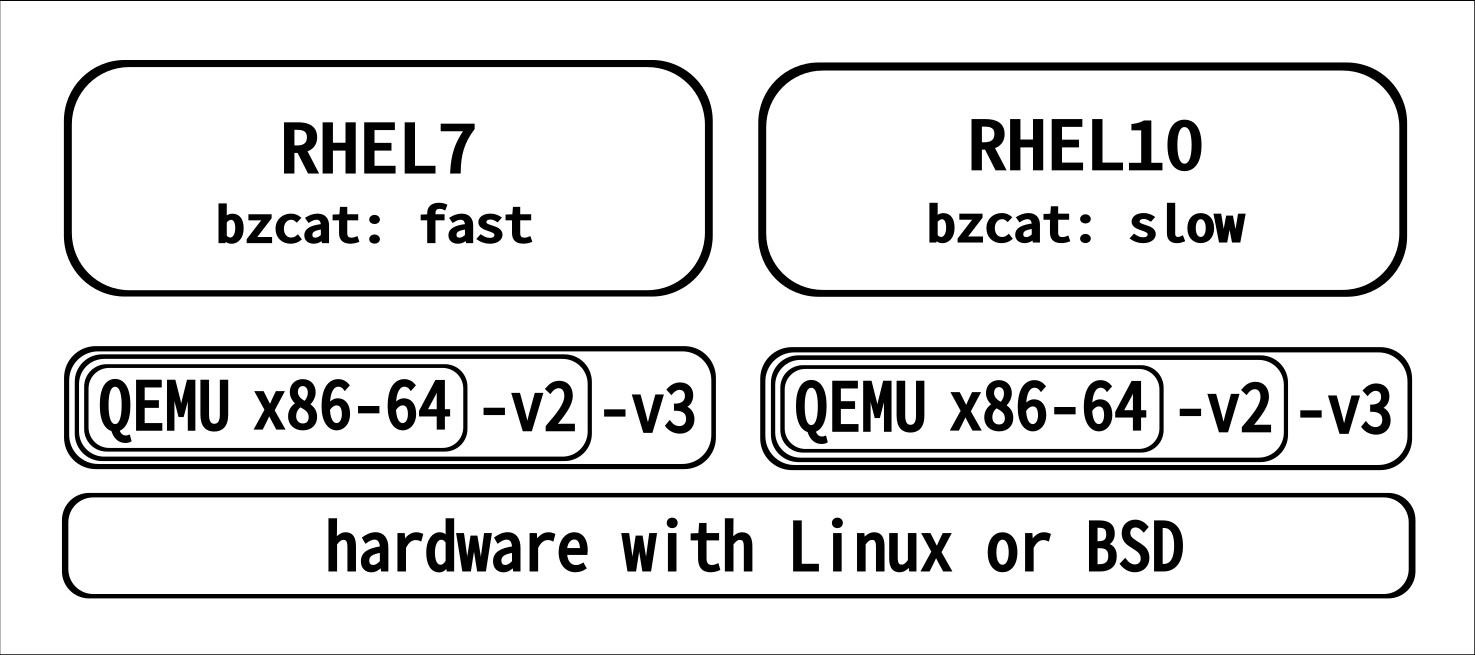
The issue si due to a side affect of the distros getting optimized to newer CPUs. Let’s consider RHEL7: released in 2014, it’s built for the x86-64 architecture. RHEL10 was released in 2025, and has glibc, one of it’s core libraries, built in a way to require CPUs of the x86-64-v3 architecture. In these 11 years, various new CPU generations have been released. Among other changes the new CPUs also got new features, so more efficient ways of doing certain computations. These are not used “automatically”, but code needs to explicitly utilize the features.
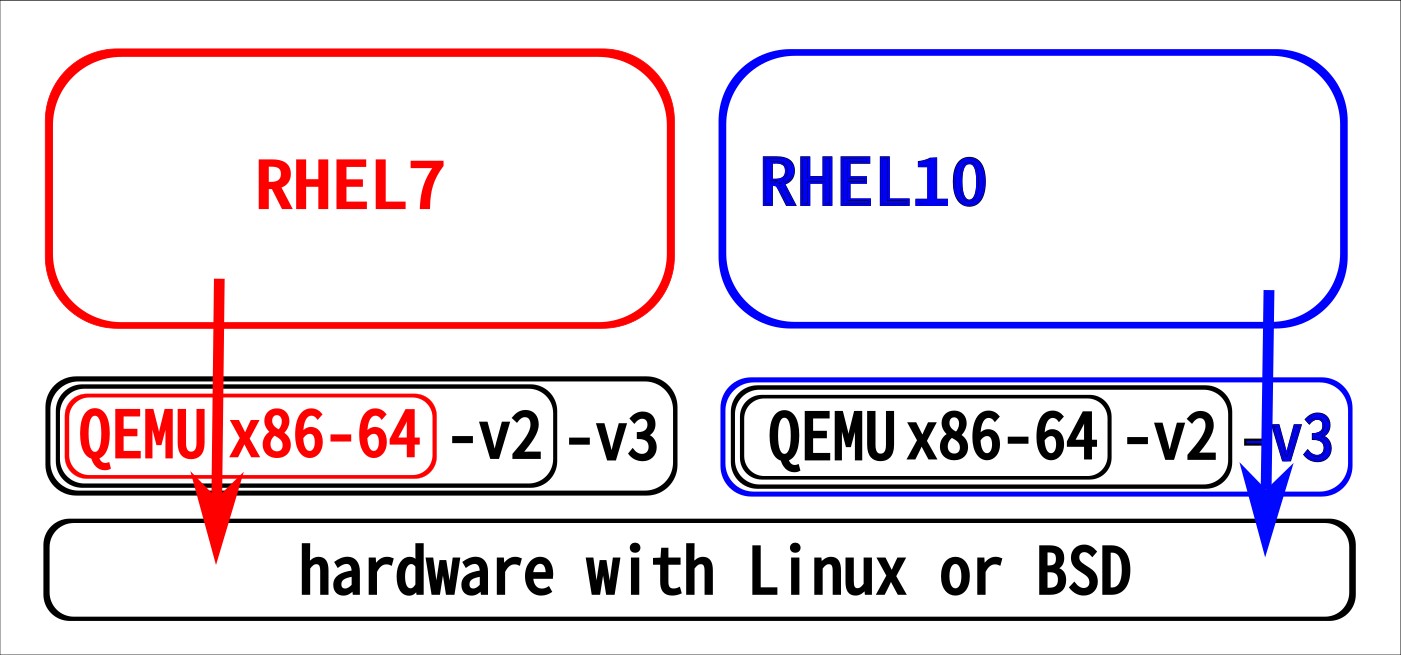
When emulating a full system with QEMU, one gets to choose which cpu features should be emulated - the recommendation is to configure as many features as possible. Our 2 VMs here are both configured with “-cpu Broadwell-v1”: that’s a CPU following the x86-64-v3 spec. RHEL7 is not utilizing the additional features over plain “x86-64”, but as RHEL10’s glibc (and thus whole RHEL10) are optimized for -v3 we really need that.
The extensions of your x86 CPU can be verified like this:
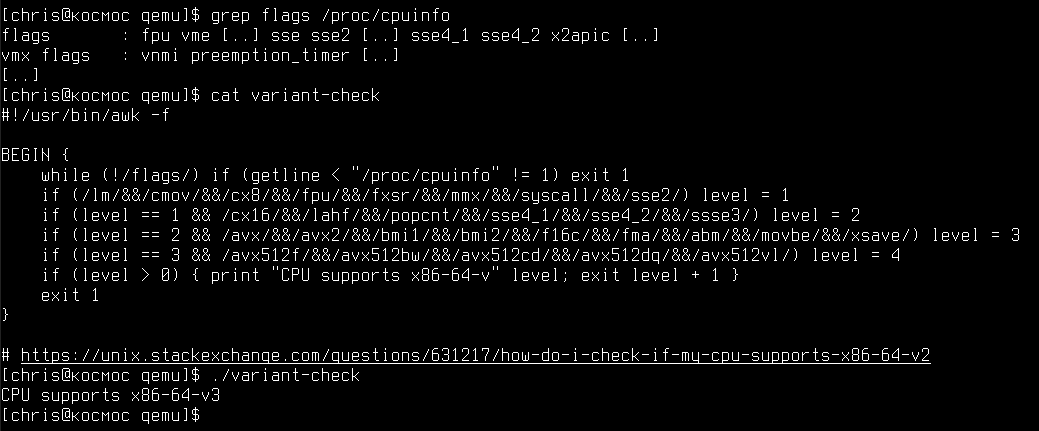
The decision makes totally sense: systems which implement -v3 and higher are available since many years, so we should utilize these features. Florian Weimer has written on this.
Now back to our emulated systems: both support -v3, but just on the emulated RHEL10 it’s getting used. RHEL7 is getting along with fewer CPU functionality, and for this whole emulated stack that turns out more performance efficient than RHEL10 where we offload things to the CPU which gets also just emulated on the host system. Qemu has a nice overview of which chipsets has which feature set.
Of course, a niche and rare situation.. but we have here no choice but emulating the whole system. :)
Fascinating to see.. and took me a ticket on qemu-devel, and explanations from colleagues to really understand this.
What do debug tools see?
So now with the explanation at hand, our overall expectation is that RHEL7 does more workload in it’s userland, and for RHEL10 we are doing more in QEMU emulating these extra registers.
For the curious, here is a text file with
- the details of the single uncompress runs
- output from “strace -c bzcat [..]” in the guests, and from “strace -c -p pidofqemu” watching from the host while data is extracted
Not sure if one can see from QEMU which cpu features are triggered, but with perf inside the guest one would be able to see that.
I tried to look at the assembler code which the workload is executing in the guest, with objdump. This brings up the asm commands for bzcat and also glibc, I compared these between rhel7 and rhel10, but did not really get anywhere. Example:
| |
Something else which might be interesting: it should be possible to have QEMU output which asm-code the guest is executing.
Containers to the rescue
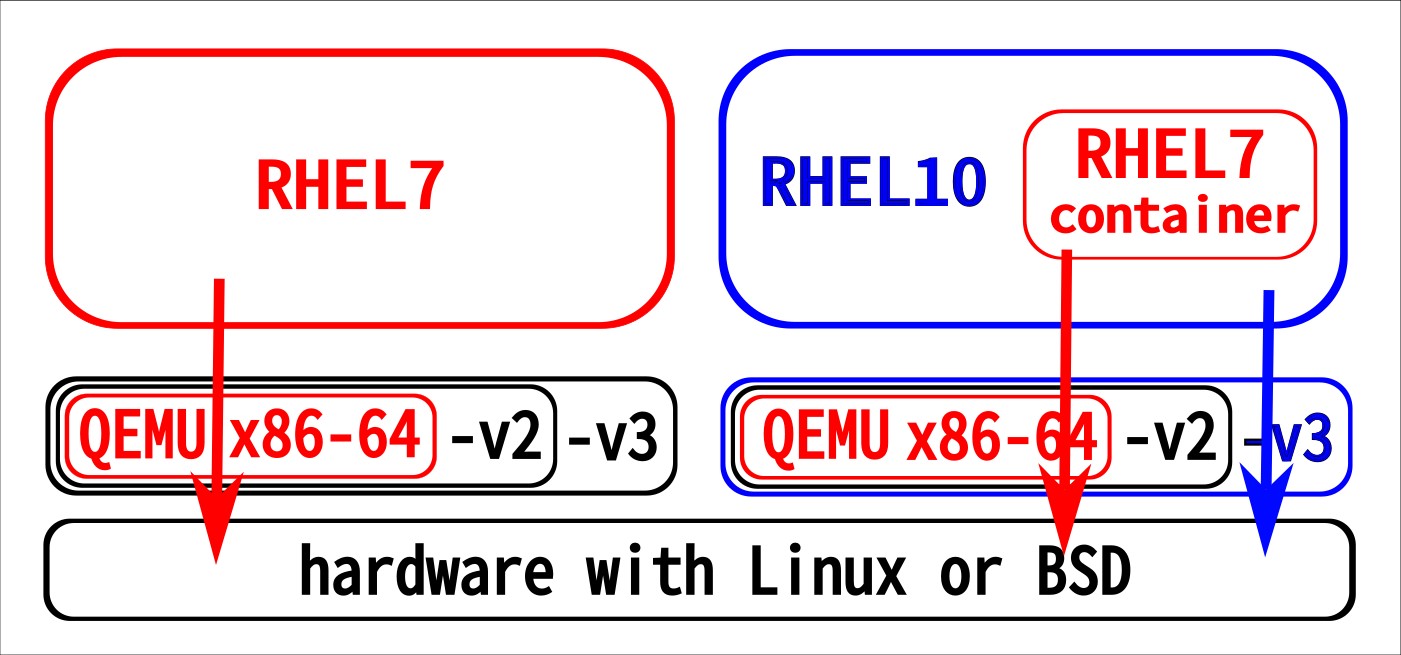
As final confirmation of the above theory, we can run the
workload in a RHEL7 container inside the RHEL10 guest:
this will utilize the containers glibc, so do computations
in the way which is more effective in our situation.
Works indeed:
| |
Average over 5 runs: 249sec, quite near to the 223sec from plain RHEL7!
Closing
To repeat: this is an exotic situation to be in, but it’s very satisfying to have understood the situation. Interestingly, AlmaLinux10 for x86 is available as a -v3 build (like RHEL10), and also as -v2 for compatability also with older CPUs. I’ll compare the download stats in one or 2 years, curious if there is much demand for -v2.
Corrections? Questions? -> Fediverse thread